
- Executive Summary: The Voice Cloning Revolution
- What is Voice Cloning? Understanding the Technology
- Why Voice Cloning Matters Now: Market Trends & Business Impact
- The Ethical Framework for Responsible Voice Cloning
- Enterprise Use Cases: Where Voice Cloning Delivers Maximum Value
- Platform Comparison: Navigating the Voice Cloning Landscape
- Individual Platform Breakdown
- Key Takeaway: Why alugha Leads in the Enterprise
- Implementation Guide: From Pilot to Scale
- The Future of Voice Cloning: Trends & Predictions
- About alugha: The Ethical Voice Cloning Pioneer
- Voice as a Biometric Identifier: Critical Privacy & Security Implications
- EU AI Act & Regulatory Compliance: Navigating the Evolving Landscape
- Risks & Limitations: A Balanced Perspective
- Synthetic Voice Detection & Forensics: Emerging Defenses
- ESG & Sustainability Considerations
- Change Management & Governance: Organizational Readiness
- Take the Next Step: Transform Your Communication with Ethical Voice Cloning
- Additional Resources
- Frequently Asked Questions
Executive Summary: The Voice Cloning Revolution
Voice cloning technology is increasingly used in enterprise communication, training, and multilingual content production, particularly in organizations operating across multiple markets.
According to various industry analysts, the voice cloning and generative voice AI market is experiencing significant growth. While market definitions vary across research firms (distinguishing between speech synthesis, conversational AI, voice biometrics, and generative audio), projections suggest the market could expand to $50-66 billion within the next decade, driven by enterprise adoption and technological advances. For many organizations, the key challenge is not whether voice cloning will be adopted, but how it can be implemented responsibly and effectively. This comprehensive guide provides a framework for enterprise decision-makers, CTOs, and compliance officers to navigate this transformative technology responsibly.
We delve into the core technology, demonstrating how artificial intelligence can create a digital replica of a human voice, enabling content creation across multiple languages and delivering significant time and cost savings in high-volume scenarios. More importantly, we address the critical ethical considerations head-on, outlining a robust framework for consent, transparency, and responsible AI that mitigates the risks of deepfakes and misuse. This article compares the leading platforms: Synthesia, HeyGen, ElevenLabs, and Respeecher and reveals how alugha’s revolutionary approach to voice cloning fundamentally differs from the competition. While others rely on avatar generation, photo-to-avatar conversion, or dubbing techniques, alugha pioneered Direct Video Voice Cloning with Segment-Level Editing, enabling natural lip-sync without video manipulation, combined with a consent-first architecture and GDPR-compliant, EU-hosted infrastructure. This positions alugha as one of the few platforms combining advanced voice cloning technology with an ethical-by-design architecture. For organizations looking to harness the power of AI voice without compromising on ethics or data sovereignty, this guide is your essential starting point.
What is Voice Cloning? Understanding the Technology

At its core, voice cloning is the process of creating a synthetic, digital replica of a person’s voice using artificial intelligence and deep learning. Unlike traditional text-to-speech (TTS) systems that rely on a library of pre-recorded, generic voices, voice cloning technology analyzes the unique characteristics of an individual’s speech, their pitch, tone, accent, cadence, breathing patterns, and emotional nuances to generate a new, highly realistic voice model. This model can then be used to articulate any written text or speak in any language, sounding highly similar to the original speaker.
How Voice Cloning Technology Works: The Technical Foundation
The magic behind voice cloning lies in deep learning, specifically using advanced neural network architectures like Transformers, diffusion models, and neural codec language models. While GANs were foundational in earlier voice cloning systems, modern state-of-the-art models increasingly rely on diffusion-based approaches and large audio models (LAMs) that offer superior quality and flexibility. The process typically involves four key stages that transform a simple voice sample into a powerful, reusable voice model.
- Data Collection: An audio sample of the target voice is recorded. While zero-shot voice cloning can work with samples as short as 10 seconds, high-quality enterprise-grade voice models typically benefit from 1-5 minutes of clean, high-fidelity audio. The quality of this sample is paramount; a clean recording in a quiet environment without background noise yields the best results and ensures the AI model captures the true essence of the speaker’s voice, including emotional nuances and prosodic patterns.
- Voice Analysis: The AI model dissects the audio sample, breaking it down into thousands of distinct phonetic and prosodic features. It learns the unique “fingerprint” of the voice, including its fundamental frequency (pitch), formants (vocal tract properties), and the subtle inflections that convey emotion and personality.
- Model Training: The neural network is trained on this voice data, creating a mathematical representation of the voice. This model understands how the speaker forms different sounds and co-articulates words, allowing it to generate new speech that adheres to the same patterns and characteristics.
- Speech Synthesis: Once the model is trained, it can synthesize new audio from any text input. When given a script, the AI generates a waveform that matches the learned vocal characteristics, effectively “speaking” the text in the cloned voice. For real-time applications, low-latency models can achieve near-real-time generation in optimized environments, though latency depends on infrastructure, model complexity, and audio quality requirements.
Voice Cloning vs. Traditional Voiceover Production
The distinction between voice cloning and traditional voiceover production represents a paradigm shift in content creation. Historically, producing a professional voiceover was a resource-intensive process involving hiring voice actors, booking studio time, recording multiple takes, and extensive post-production work. This could take weeks and cost thousands of dollars for a single piece of content. Voice cloning disrupts this model entirely, making professional-quality voiceovers accessible to organizations of all sizes.
| Aspect | Traditional Voiceover | AI Voice Cloning |
|---|---|---|
| Time Required | Days to Weeks | Minutes |
| Cost Per Project | $500 – $5,000+ | $10 – $50 or subscription |
| Scalability | Limited by actor availability | Infinite; generate 24/7 |
| Revisions | Requires re-recording (costly) | Instant; edit text and regenerate |
| Language Support | Requires hiring new actors | Instantly generate in 175+ languages |
| Voice Consistency | Varies between sessions | 100% consistent voice |
Why Voice Cloning Matters Now: Market Trends & Business Impact
The rapid adoption of voice cloning is not merely a technological trend; it is a strategic business imperative. As global markets become more interconnected and digital content consumption continues to soar, the ability to communicate effectively and authentically across multiple languages and channels has become a key differentiator. The voice cloning market is experiencing significant growth. While market definitions and analyst projections vary, industry reports suggest double-digit annual growth rates, with some forecasts estimating the market could exceed $50-66 billion within the next decade. This surge is fueled by the tangible return on investment (ROI) and competitive advantages that early adopters are already realizing.
Business Impact & Return on Investment
Early enterprise adopters report measurable improvements in production speed and localization workflows. The most significant impact is the dramatic reduction in time and cost associated with content creation. Projects that once took weeks of coordination with voice actors and sound studios can now be completed in minutes, leading to time savings of 70-90% in high-volume, multilingual scenarios. This agility allows organizations to respond to market changes, launch campaigns, and distribute internal communications with unprecedented speed. The corresponding cost savings can be substantial when scaling across multiple languages and frequent content updates, freeing up significant budget that can be reallocated to other strategic initiatives. However, cost-benefit analysis should account for setup time, quality assurance, and the specific use case, single projects or premium brand content may not achieve the same savings as high-volume training or internal communication programs. The ability to generate voiceovers in 200+ languages (with quality varying depending on linguistic complexity and available training data) eliminates the high costs of hiring local voice talent for many use cases, making global expansion economically viable for a wider range of projects.
Current Market Trends Shaping Voice Cloning
Several key trends are shaping the voice cloning landscape and driving enterprise adoption:
- From Generic to Personal: The market is decisively shifting away from generic, robotic-sounding TTS voices toward highly realistic, personalized voice clones that reflect a brand’s unique identity and resonate with audiences.
- Integrated Content Platforms: Leading providers are no longer offering voice as a standalone feature. Instead, they are integrating it deeply into comprehensive video creation and content management platforms, like Synthesia and HeyGen.
- The Rise of Real-Time Voice Agents: Low-latency models are enabling the deployment of conversational AI voice agents in customer service, transforming contact centers and user support. While sub-100ms latency is achievable in optimized environments, real-world performance depends on infrastructure, model complexity, and quality requirements.
- Ethical AI as a Prerequisite: As the technology becomes more powerful, a strong ethical framework is transitioning from a “nice-to-have” to a non-negotiable requirement for enterprise adoption.
- Regulatory Scrutiny: Governments worldwide are establishing regulatory frameworks like the EU AI Act, which classifies certain AI applications as “high-risk” and mandates strict compliance regarding transparency and consent.
The Ethical Framework for Responsible Voice Cloning

The power of voice cloning comes with significant ethical responsibilities. The ability to perfectly replicate a human voice opens the door to potential misuse, including the creation of deepfakes, fraud, and the spread of misinformation. For enterprises, navigating these risks is not just a matter of legal compliance but a cornerstone of maintaining brand trust and integrity. A robust ethical framework for voice cloning must be built on the pillars of consent, transparency, and accountability.
Core Ethical Concerns in Voice Cloning
The primary ethical challenge is ensuring informed consent. A human voice can become biometric data when it is processed for the purpose of uniquely identifying an individual, and its use must be explicitly authorized. This means having a clear, unambiguous agreement that specifies exactly how the voice clone will be used, for what duration, and in what contexts. Without a valid legal basis or explicit consent, the use of a cloned voice may violate privacy and data protection laws. Other concerns include ensuring accountability for AI-generated content and preventing the technology from being used to impersonate individuals without permission.
Responsible AI Best Practices for Voice Cloning
To counter these risks, the industry is converging on a set of best practices for responsible AI:
- Consent-First Approach: No voice should be cloned without the explicit, written permission of the individual. This is the foundational principle of ethical voice cloning.
- Radical Transparency: All content generated using a cloned voice should be clearly and conspicuously labeled as AI-generated. This prevents deception and ensures audiences are aware of the content’s origin.
- Audio Watermarking: An inaudible digital watermark should be embedded in all AI-generated audio. This allows for the identification and tracking of synthetic media, helping to curb its misuse.
- Secure Data Governance: Voice data must be treated as sensitive personal information, protected with end-to-end encryption, and stored in secure, compliant environments (e.g., GDPR-compliant EU data centers).
- Clear Usage Policies: Platform providers must enforce strict terms of service that prohibit the use of their technology for malicious purposes, including harassment, fraud, or political misinformation.
alugha’s Ethical Framework: Setting a New Industry Standard
From its inception, alugha has engineered its voice cloning technology around these ethical principles. We believe that true innovation cannot come at the expense of human dignity and trust. Our platform is one of the first to be built on a consent-first architecture, where every voice clone is tied to a verifiable consent agreement. We combine this with a commitment to data sovereignty, hosting all data within the European Union to ensure full GDPR compliance. This ethical foundation is not an afterthought; it is our core differentiator and our promise to our customers that they can innovate responsibly.
Enterprise Use Cases: Where Voice Cloning Delivers Maximum Value
The applications of ethical voice cloning in the enterprise are vast and transformative, extending far beyond simple cost savings. By enabling scalable, personalized, and multilingual audio content, the technology is unlocking new efficiencies and creating more inclusive experiences across the entire organization.
Training & Development: Multilingual Learning at Scale
Corporate learning and development (L&D) is one of the most powerful use cases for voice cloning. Global organizations can now create centralized compliance training, employee onboarding, and skill development courses and instantly deploy them across a wide range of languages and dialects (with quality varying by language complexity and available training data). Instead of a patchwork of regional training materials with inconsistent messaging, a single, trusted corporate voice can deliver a unified message to every employee in their native language. This not only ensures consistency but also dramatically improves engagement and knowledge retention. Companies using this approach in high-volume, multilingual scenarios have reported time savings of 70-90% in training content creation and cost reductions when scaling across multiple languages and frequent updates.
Localization & Global Reach: Breaking Language Barriers
Voice cloning shatters the language barrier for global marketing and communications. A CEO can record a single message, and within minutes, it can be delivered to employees, customers, and partners worldwide in their own language, while retaining the original tone and authority of the speaker. This capability allows brands to maintain a consistent and authentic voice across all markets, fostering a stronger global identity. The need to source, vet, and manage dozens of local voice actors is eliminated, enabling marketing teams to launch global campaigns with unprecedented speed and efficiency.
Accessibility & Inclusion: Making Content Universally Accessible
Approximately 16% of the world’s population lives with some form of disability, including visual impairments and learning disabilities like dyslexia. Voice cloning is a powerful tool for creating a more inclusive digital environment. By converting all written content—from internal documents and website copy to product manuals and support articles—into natural-sounding audio, organizations can ensure that their information is accessible to everyone. This not only helps in meeting regulatory requirements like the Americans with Disabilities Act (ADA) and the European Accessibility Act but also fosters a culture of inclusivity that strengthens employee engagement and customer loyalty.
Customer Service & Support: 24/7 Multilingual Assistance
The next generation of customer service is powered by AI voice agents. Leveraging ultra-low latency voice cloning, companies can deploy 24/7 multilingual support bots that sound genuinely human and helpful. These agents can handle common queries, process requests, and provide information, freeing up human agents to focus on more complex and high-value interactions. This leads to significant operational efficiencies, with some companies reporting an 80% lower cost per interaction compared to traditional call centers, all while improving customer satisfaction through instant, on-brand support in any language.
Marketing & Sales: Personalization at Scale
In a crowded digital landscape, personalization is key to standing out. Voice cloning enables sales and marketing teams to create highly personalized outreach at scale. Imagine sending a prospective customer a product demo video where the voiceover addresses them by name, or a follow-up message that speaks directly to their industry’s pain points. This level of personalization, which was previously impossible to scale, can lead to a 40% higher conversion rate by creating a more direct and engaging connection with the audience.
Platform Comparison: Navigating the Voice Cloning Landscape
The voice cloning market is crowded and evolving rapidly. To help you navigate the options, we’ve compared the leading platforms across a consistent framework, evaluating their voice quality, language support, ethical posture, and enterprise readiness. The key players, Synthesia, HeyGen, ElevenLabs, and Respeecher, each have distinct strengths, but a closer look reveals critical differences in their approach, particularly concerning ethics and data sovereignty.
Comprehensive Platform Comparison Table (March 2026)
| Feature | Synthesia | HeyGen | ElevenLabs | Respeecher | alugha |
|---|---|---|---|---|---|
| Primary Focus | AI Video Platform | AI Avatar Platform | AI Voice Generation | Professional Dubbing | Ethical Multilingual Comms |
| Voice Quality | Good | Excellent | Excellent | Professional | Excellent |
| Languages Supported | 160+ | 175+ | 70+ | Limited | 200+ |
| Video Integration | Native | Native | API | Limited | Native |
| Ethical Framework | Basic | Basic | Developing | Strong | Industry-Leading |
| Data Sovereignty | US-based | US-based | US-based | EU-based | EU-based (Germany) |
| GDPR Compliance | Partial | Partial | Partial | Yes | Yes (by design) |
| Real-time Voice Agents | No | No | Yes | No | Yes |
| Lip-Sync Technology | Avatar-based | Avatar IV AI Sync | Photo-to-Avatar | Dubbing-based | Direct Video Voice Cloning + Segment Editing |
| Segment-Level Voice Editing | Limited | Limited | Limited | No | Yes – Full Control |
| Natural Lip-Sync (No Video Manipulation) | No (Avatar-generated) | No (Avatar-generated) | No (Photo-based) | No (Dubbing-based) | Yes – Revolutionary |
| Best For | Integrated Video/Voice | Hyper-realistic Avatars | Voice-first Applications | Hollywood & Gaming | Ethical Enterprise Use + Native Video |
Detailed Competitor Analysis: Understanding the Technology Gap
The voice cloning market is fundamentally divided by technological approach. Most competitors follow a Video-to-Audio model: they generate new video (or avatars) and then sync audio to it. alugha, by contrast, pioneered the Audio-to-Video model: it preserves the original video and adapts audio to match it. This distinction has profound implications for enterprise use cases.
The Video-to-Audio Approach (Synthesia, HeyGen, ElevenLabs)
These platforms generate new video content (or avatars) and then synchronize audio to the generated visuals. While visually impressive, this approach has significant limitations for professional enterprises:
- Visual Artifacts & Uncanny Valley: Generated or manipulated video can exhibit synthetic facial movements, unnatural expressions, or subtle deepfake tells that undermine authenticity.
- Storage & Bandwidth Explosion: For 10 languages, you need 10 separate video files. A global enterprise with thousands of training videos faces exponential storage and hosting costs.
- Limited Collaboration: Once a video is rendered, corrections are expensive. You cannot easily refine or adjust the output without re-rendering.
- Regulatory & Brand Risk: Visual manipulation may violate regulatory requirements or brand guidelines, especially in healthcare, law, and finance.
The Audio-to-Video Approach (alugha)
alugha preserves the original video and adapts audio to match the visual performance. This approach delivers distinct advantages:
- Authentic Performance: The original actor, speaker, or executive remains visually unchanged. Viewers see genuine performance, genuine emotion, genuine authenticity.
- Multitrack Efficiency: One video file with multiple audio tracks (like a DVD). Users switch languages without downloading 10 separate files.
- Collaboration-Ready: Native speakers and linguists can refine audio before deployment using alugha’s “dubbr” tool. Corrections are quick and inexpensive.
- Regulatory Compliance: No visual manipulation means no regulatory concerns. Perfect for healthcare, legal, and compliance-sensitive content.
- Cost Efficiency: Massive savings in storage, bandwidth, and infrastructure. For enterprises managing thousands of videos globally, this translates to millions in savings.
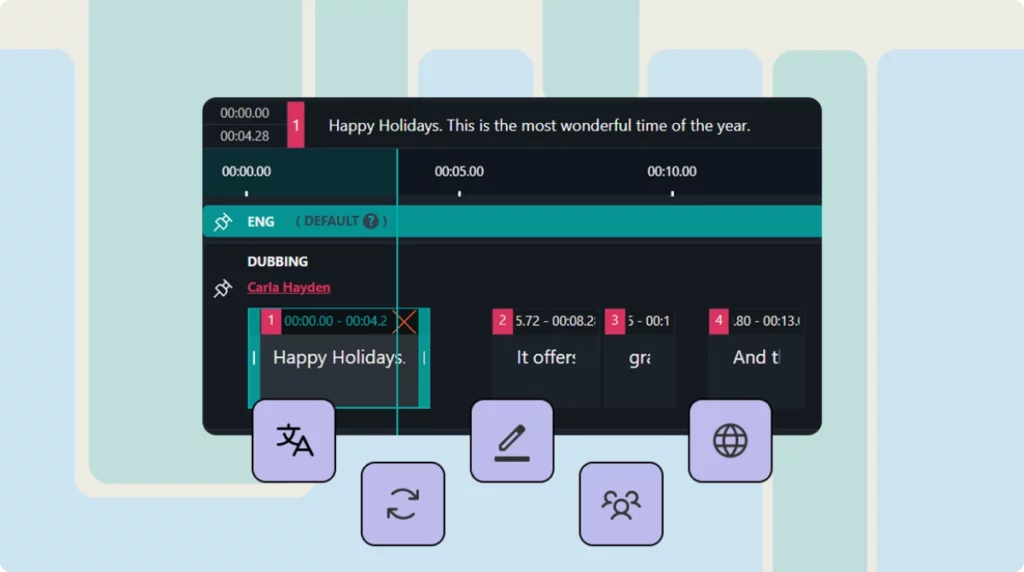
Individual Platform Breakdown
Synthesia has established itself as a leader in the AI video space, offering a robust platform that tightly integrates voice cloning with avatar creation. Its Express-2 engine provides AI-driven lip-sync for avatars, but this is avatar-generated rather than native video-based. Its strength lies in its ease of use for corporate training and internal communications. However, as a US-based company, it presents data sovereignty challenges for EU organizations, and its ethical framework is less developed than those of its EU counterparts.
HeyGen excels at creating hyper-realistic avatars with its Avatar IV engine, which includes advanced AI lip-sync capabilities. However, this lip-sync is avatar-generated, meaning the system creates synthetic facial movements rather than working with native video content. Its focus is primarily on marketing and sales use cases where visual appeal is paramount. Like Synthesia, it is US-based, and its approach to voice cloning ethics is not as central to its platform as it is for alugha.
ElevenLabs is the specialist in voice generation, widely recognized for producing highly natural-sounding synthetic voices and emotionally nuanced AI voices on the market. Recently, ElevenLabs has added lip-sync capabilities through a photo-to-avatar approach, allowing users to create talking avatars from static images. However, this is not native video-based voice cloning; it converts photos into avatars with lip-sync. Its low-latency models are ideal for building real-time voice agents. However, its platform is voice-first and requires API integration for video, and it also operates under US jurisdiction.
Respeecher caters to the high-end entertainment market, providing professional-grade voice cloning and synthetic film dubbing for major films and video games. Its lip-sync technology is dubbing-based, meaning it synchronizes new audio to existing video through advanced dubbing techniques rather than native voice cloning from video. It has a strong ethical framework but offers limited scalability and language support for broad enterprise use cases, and is primarily designed for professional studios rather than enterprise self-service.
Key Takeaway: Why alugha Leads in the Enterprise
For organizations prioritizing ethical AI, data sovereignty, and GDPR compliance, alugha distinguishes itself through a revolutionary approach to voice cloning that is fundamentally different from its competitors. While Synthesia and HeyGen rely on avatar-generated lip-sync, ElevenLabs uses photo-to-avatar conversion, and Respeecher employs dubbing-based techniques, alugha pioneered the Audio-to-Video Principle with Direct Video Voice Cloning and Segment-Level Editing. This means:
- Authentic Video Preservation: alugha clones voices directly from your video without requiring separate voice samples or avatar generation. The original video—the genuine performance, authentic mimicry, real actor, remains completely untouched.
- Surgical Audio Adaptation: Every speech segment can be edited individually. By shifting segments and inserting strategic pauses, alugha stretches or compresses the new language to match the original lip movements, the perfection of classical dubbing through AI tools.
- Multitrack Efficiency: One video file with multiple audio tracks (like a DVD). Users switch languages without downloading separate files. For global enterprises, this eliminates millions in storage and bandwidth costs.
- No Uncanny Valley: Because the video remains untouched, there are no artificial artifacts, no synthetic facial movements, no deepfake tells. Viewers see genuine performance with authentic audio.
- Regulatory Compliance & Brand Integrity: Many enterprises, especially in healthcare, law, and finance, cannot allow visual manipulation. alugha preserves content integrity while enabling global reach.
- Collaboration-Ready: Native speakers and linguists can refine AI-generated audio using alugha’s “dubbr” tool. Corrections are quick and inexpensive, unlike visual deepfake approaches that require expensive re-rendering.
- Ethical by Design: Combined with EU-based data hosting on Hetzner infrastructure and a consent-first architecture, alugha offers a fundamentally different value proposition: revolutionary technology built on ethical foundations.
- For enterprises that cannot afford to compromise on data protection, brand authenticity, regulatory compliance, or ethical AI practices, alugha represents a new category of solution – one that doesn’t force a trade-off between innovation and responsibility. While competitors chase visual spectacle, alugha delivers the precision, authenticity, and efficiency that professional organizations demand.
Implementation Guide: From Pilot to Scale
Adopting voice cloning technology requires a strategic approach. A successful implementation moves from a small, controlled pilot project to a full-scale organizational rollout. The key is to start with a clear use case, measure the impact, and build on that success.
Best Practices for Voice Cloning Implementation

To ensure a smooth and ethical implementation, follow these best practices:
- Start with High-Quality Audio: The quality of your cloned voice depends entirely on the input sample. Record in a quiet room using a professional-grade microphone to capture the full richness of the speaker’s voice.
- Secure Explicit Consent: Always obtain written consent before cloning a voice. The agreement should clearly state the intended use and duration, protecting both the speaker and the organization.
- Be Transparent: Clearly label all AI-generated content to avoid deceiving your audience. This builds trust and ensures compliance with emerging regulations.
- Test Rigorously: Before deploying a cloned voice in a customer-facing application, test it extensively to ensure it aligns with your brand’s tone and quality standards.
- Establish Strong Governance: Create internal policies that define who can use the technology, for what purpose, and under what conditions.
Enterprise Evaluation Framework
When evaluating platforms, use this framework to make an informed decision:
- Ethical Framework: Does the platform have a clear, enforceable policy on consent and transparency?
- Data Sovereignty & Compliance: Where is the data hosted? Is the platform fully GDPR compliant?
- Voice Quality: How natural and emotionally expressive is the generated voice?
- Integration Capabilities: Does the platform offer a robust API and integrate with your existing systems (LMS, CRM, etc.)?
- Scalability & Reliability: Can the platform handle your organization’s volume and provide an enterprise-grade SLA?
The Future of Voice Cloning: Trends & Predictions
Voice cloning technology continues to evolve rapidly as advances in large audio models and speech synthesis improve quality, latency, and multilingual capabilities. In the coming years, we can expect to see the emergence of real-time voice synthesis with near-perfect emotional intelligence, allowing for truly natural human-AI conversations. The technology will become more deeply integrated into our daily workflows, from voice-activated software to fully autonomous content creation systems. As this happens, the importance of ethical frameworks and regulatory compliance will only intensify. The platforms that lead the next wave of innovation will be those that build their technology on a foundation of trust and responsibility.
About alugha: The Ethical Voice Cloning Pioneer
alugha is a German-based AI platform that is revolutionizing how enterprises communicate globally through ethical, multilingual video and voice solutions. Founded on the principle that innovation must never compromise on ethics or data protection, alugha has positioned itself as a leading platform in responsible AI voice cloning.
Why alugha is the Clear Choice for Enterprise Voice Cloning
While competitors focus on features and scale, alugha has taken a fundamentally different approach. We recognized early that the true power of voice cloning could only be unlocked if the technology was built on an unshakeable ethical foundation. This philosophy permeates every aspect of our platform.
Ethical by Design: Our consent-first architecture is not a compliance checkbox; it is the core of our platform. Every voice clone is tied to explicit, verifiable consent. We believe that individuals’ voices are their own, and their permission is non-negotiable.
Data Sovereign by Default: As a German company, alugha is subject to the strictest data protection regulations in the world. All customer data is hosted exclusively within the European Union, ensuring full GDPR compliance and protecting your organization’s data from foreign surveillance and unauthorized access.
Integrated by Nature: Unlike point solutions that require complex integrations, alugha provides a seamless, all-in-one platform for creating, managing, and distributing multilingual video and audio content. From training videos to marketing campaigns, customer service agents to internal communications, alugha handles it all with a unified interface and consistent quality.
Real-World Success: Customer Results
Our customers across finance, technology, manufacturing, and healthcare are already experiencing the transformative power of ethical voice cloning:
- Financial Institution: Achieved 75% time savings in compliance training creation while ensuring consistent, multilingual messaging across their global workforce.
- Technology Company: Reduced localization costs by 60% by generating product demos and marketing materials in over 50 languages instantly.
- Manufacturing Leader: Improved employee satisfaction by 95% by delivering multilingual training in employees’ native languages, fostering a more inclusive workplace.
- Healthcare Provider: Enhanced patient communication by deploying multilingual voice agents for appointment scheduling and follow-up care, reducing administrative burden by 80%.
alugha’s Revolutionary Technology: The Audio-to-Video Principle
What truly sets alugha apart is its groundbreaking approach to voice cloning. Unlike competitors who rely on avatar generation, photo-to-avatar conversion, or visual deepfake techniques, alugha pioneered a fundamentally different technology: the Audio-to-Video Principle. Instead of manipulating the video to fit new audio, alugha surgically adapts the audio to match the original video, preserving authenticity, integrity, and the genuine performance of the original speaker.
The Audio-to-Video Approach: Why It Matters
- Direct Video Voice Cloning: alugha’s AI clones voices directly from your video content. No need for separate voice samples, no avatar generation, no complex setup. Simply upload your video, and the system extracts and clones the voice automatically. The AI “listens” to the speaker, learns their unique timbre, accent, and emotional patterns, and generates new speech in that exact voice.
- Segment-Level Editing (Multitrack Technology): Every speech segment in your video can be edited individually. By shifting segments and inserting strategic pauses, alugha stretches or compresses the new language to match the original lip movements. This is essentially the perfection of classical dubbing through AI tools, giving you surgical precision over every syllable.
- No Visual Manipulation = No Uncanny Valley: Because the original video remains untouched, there are no artificial artifacts: no twitching mouth corners, no synthetic facial movements, no “deepfake” tells. The viewer sees the genuine performance, the authentic mimicry, the real actor – only the audio has changed.
- One Video, Many Languages (Multitrack Architecture): Unlike competitors who generate separate videos for each language, alugha uses a multitrack approach. You have one video file with multiple audio tracks. Users simply switch languages like on a DVD. This saves enormous storage, bandwidth, and hosting costs, a massive advantage for enterprises managing global content.
- Multilingual Localization with Authenticity: Clone and adapt voices across 200+ languages, maintaining almost perfect lip-sync in every language. Your original speaker’s voice characteristics are preserved while speaking fluently in any language. The result is a localized video that feels authentic, not artificial.
Why This Matters for Enterprise: Authenticity, Compliance & Efficiency
For professional organizations, alugha’s Audio-to-Video approach solves critical business problems that visual deepfake approaches cannot:
- Brand & Legal Integrity: Many enterprises, especially in healthcare, law, finance, and high-end marketing, cannot allow visual manipulation of their content. Regulatory bodies, legal teams, and brand guidelines often prohibit altering the visual presentation of executives, medical professionals, or legal statements. alugha preserves the original video’s integrity while enabling global reach through audio localization.
- Collaboration & Quality Control: alugha’s “dubbr” tool allows native speakers and linguists to refine AI-generated audio before deployment. This human-in-the-loop approach ensures cultural accuracy and linguistic nuance. In contrast, visual deepfake videos are “finished” once rendered—corrections require expensive re-rendering.
- Storage & Bandwidth Efficiency: One video with multiple audio tracks (multitrack) vs. 10 separate videos for 10 languages. For a global enterprise with thousands of training videos, this difference translates to millions in infrastructure savings.
- Workflow Advantage: Voice cloning “out of the box” means no hours spent uploading training data. The AI learns from your video immediately, generates the new language in the same voice, and is ready for refinement. This dramatically reduces time-to-market for global content.
Enterprise-Grade Features & Compliance
alugha is built for enterprise from the ground up, offering the features and compliance capabilities that large organizations demand:
- GDPR Compliance: Full compliance with GDPR, CCPA, and emerging AI regulations like the EU AI Act.
- Security & Encryption: End-to-end encryption, SOC 2 Type II certification, and enterprise-grade security protocols.
- Scalability: Handle millions of voice clones and billions of voice generation requests without performance degradation.
- API & Integration: Robust REST API for seamless integration with your existing systems (LMS, CRM, video platforms, etc.).
- Multilingual Support: 200+ languages and dialects, with continuous expansion to support emerging markets.
- Real-Time Voice Agents: Deploy conversational AI voice agents with ultra-low latency for real-time customer interactions.
- Dedicated Support: Enterprise-grade support with dedicated account managers and SLA guarantees.
The alugha Commitment: Innovation with Integrity
At alugha, we believe that the future of AI is not about who can build the most powerful technology, but who can build it most responsibly. We are committed to being a force for good in the AI industry, setting the standard for ethical practices and inspiring other companies to follow suit. When you choose alugha, you are not just choosing a platform; you are choosing a partner that shares your commitment to innovation, integrity, and the responsible use of AI.
Voice Cloning vs. Standard AI Voices
In our example, you can see the difference between voice cloning and standard AI voices. Please listen to the original in English first before trying the other languages.
Standard AI Voices
Voice Cloning
Voice as a Biometric Identifier: Critical Privacy & Security Implications
A critical aspect often overlooked in voice cloning discussions is that a human voice is a biometric identifier, similar to fingerprints or facial features. Under GDPR Article 9, biometric data is classified as a special category of personal data requiring heightened protection. This has profound implications for how organizations must handle voice data throughout its lifecycle.
Voice Data Classification & GDPR Article 9
Because voice is biometric data, any collection, processing, or storage of voice samples requires explicit legal basis under GDPR. Organizations must implement strict data minimization principles, ensuring they collect only the voice data necessary for the specific, declared purpose. Additionally, voice data must be subject to the same rigorous security controls as other sensitive biometric information, with encryption, access controls, and audit trails.
Voice Spoofing & Identity Fraud Risks
As voice cloning technology becomes more sophisticated, the risk of voice spoofing, using a cloned voice to impersonate someone, increases significantly. This poses direct threats to organizations that rely on voice authentication systems (e.g., banking, customer service). Enterprises must implement additional security measures, such as multi-factor authentication and liveness detection, to prevent unauthorized access through voice-based fraud.
Interaction with Voice Authentication Systems
Organizations that use voice biometrics for authentication must carefully evaluate the security implications of deploying voice cloning technology in the same environment. The presence of high-quality voice clones could potentially weaken voice authentication security if not properly managed. A comprehensive security architecture must account for both the benefits of voice cloning and the risks it introduces to biometric authentication systems.
EU AI Act & Regulatory Compliance: Navigating the Evolving Landscape

The EU AI Act, which entered into force in 2024, introduces phased transparency requirements for AI-generated content. By 2026, providers of synthetic media such as cloned voices must meet specific transparency obligations. Enterprises must ensure that all cloned voices are clearly labeled as AI-generated to remain compliant and avoid significant penalties.
Risk Classification & Voice Cloning
Voice cloning applications can fall into different risk categories depending on their use case:
- High-Risk Applications: Using voice cloning for biometric identification, emotion recognition, or real-time surveillance may be classified as high-risk, requiring comprehensive risk assessments and compliance documentation.
- Limited-Risk Applications: Deploying voice cloning for training, internal communications, or customer service may fall into limited-risk categories, requiring transparency and disclosure.
- Prohibited Applications: Certain uses, such as creating deepfakes for political manipulation or non-consensual impersonation, may be outright prohibited under the Act.
Transparency & Disclosure Requirements
The EU AI Act mandates that organizations disclose when content is AI-generated. For voice cloning specifically, this means clearly labeling all synthetic audio and providing users with information about the AI system’s capabilities and limitations. Organizations must also maintain documentation of their risk assessment processes and demonstrate compliance through audit trails and logging obligations.
Documentation & Compliance Obligations
Organizations deploying voice cloning must maintain comprehensive documentation including:
- Risk assessment reports detailing potential harms and mitigation strategies
- Consent records demonstrating explicit authorization for voice cloning
- Audit logs tracking all access to voice data and cloned content
- Transparency statements and disclosure mechanisms for end users
- Data retention and deletion policies compliant with GDPR
Risks & Limitations: A Balanced Perspective
While voice cloning offers tremendous potential, it is important to acknowledge its limitations and risks. A balanced assessment helps organizations make informed decisions about when and how to deploy the technology.
Quality & Authenticity Limitations
Despite significant advances, current voice cloning technology has notable limitations:
- Emotional Authenticity: While voice clones can reproduce pitch and tone, capturing genuine emotional nuance remains challenging. Irony, sarcasm, and subtle emotional cues may not translate convincingly to synthetic audio.
- Synthetic Fatigue: Extended listening to synthetic voices can cause listener fatigue and reduced engagement, particularly for long-form content like audiobooks or extended training modules.
- Language-Specific Challenges: Tonal languages, complex phonetic systems, and rare languages present technical challenges that limit the quality of voice cloning in non-English contexts.
Reputational & Social Risks
Organizations deploying voice cloning face potential reputational risks if not handled transparently:
- Public Backlash: Consumers and employees may react negatively to AI-generated voices if they perceive deception or lack of transparency.
- CEO Voice Misuse: Malicious actors could attempt to impersonate executives, creating significant security and reputational risks.
- Social Engineering Threats: Voice clones could be weaponized in social engineering attacks, phishing campaigns, or fraud schemes.
Legal & Ethical Gray Areas
Several emerging legal questions remain unresolved:
- Posthumous Voice Cloning: Can an organization clone a deceased person’s voice? Who owns the rights to that voice?
- Employee Voice Ownership: If an employee’s voice is cloned for corporate training, who retains rights to that voice after employment ends?
- Voice Actor Licensing: How should organizations license voices from professional speakers or voice actors? What are fair compensation models?
Synthetic Voice Detection & Forensics: Emerging Defenses
As voice cloning becomes more sophisticated, the ability to detect synthetic audio becomes increasingly important. Organizations need to understand both the capabilities and limitations of current detection technologies.
Audio Watermarking & Forensic Techniques
Several approaches are emerging to identify and track synthetic audio:
- Inaudible Watermarks: Digital watermarks embedded in synthetic audio allow organizations to track the origin and usage of cloned content. However, watermarks can potentially be removed with advanced audio processing.
- Spectral Analysis: Forensic techniques analyzing the frequency spectrum of audio can sometimes identify artifacts characteristic of synthetic speech, though sophisticated models may evade detection.
- Machine Learning Detectors: AI-based detection systems trained on synthetic audio can identify deepfakes with varying degrees of accuracy, but they require continuous updating as generation models improve.
Robustness & Limitations of Detection
It is important to note that no detection method is foolproof. As voice cloning technology advances, detection systems must continuously evolve. Organizations should not rely solely on detection as a security mechanism; instead, a multi-layered approach combining detection, watermarking, authentication, and transparency is essential.
ESG & Sustainability Considerations
As enterprises increasingly prioritize Environmental, Social, and Governance (ESG) criteria, the sustainability implications of voice cloning technology deserve attention.
Energy Consumption & Carbon Footprint
Training and running large language models and voice cloning systems requires significant computational resources, translating to substantial energy consumption and carbon emissions. Organizations should evaluate:
- The energy efficiency of different voice cloning platforms
- Whether providers use renewable energy sources for their data centers
- The carbon footprint of model training versus the carbon savings from eliminating traditional voiceover production
Green AI Initiatives
Forward-thinking voice cloning providers are implementing “Green AI” practices, optimizing models for efficiency and reducing computational overhead. When evaluating platforms, organizations should inquire about sustainability commitments and carbon offset programs.
Change Management & Governance: Organizational Readiness
Successful voice cloning adoption requires more than technology; it requires organizational readiness, clear governance, and thoughtful change management.
Employee Acceptance & Concerns
Organizations must address legitimate concerns from employees and stakeholders:
- Job Displacement Fears: Voice actors and audiobook narrators may fear job loss. Transparent communication about how voice cloning will be used and where human talent remains essential is critical.
- Ethical Concerns: Employees may have concerns about the ethical implications of voice cloning. Clear policies and ethical frameworks help build trust.
- Governance Committees: Establishing cross-functional governance committees (including HR, Legal, Compliance, and IT) ensures responsible deployment and addresses concerns early.
Procurement & SLA Considerations
When selecting a voice cloning provider, organizations should clarify critical operational questions:
- Service Level Agreements (SLAs): What uptime guarantees and performance commitments does the provider offer?
- Model Retraining & Updates: How frequently are models updated? What is the process for retraining custom voice models?
- Data Deletion Policy: What is the retention period for voice data? Can organizations request complete deletion?
- Exit Strategy: If the organization decides to switch providers, what data export and migration support is available?
Cybersecurity & Emerging Threats
Voice cloning introduces new cybersecurity attack vectors that organizations must defend against:
- Prompt Injection Attacks: Voice agents powered by large language models may be vulnerable to prompt injection, where attackers craft inputs to manipulate the system’s behavior.
- Audio-Based Phishing: Attackers could use cloned voices to conduct sophisticated phishing campaigns, impersonating trusted individuals.
- Voice Data Breaches: If voice data is compromised, attackers gain access to biometric information that cannot be changed like passwords.
A comprehensive security strategy should include voice data encryption, access controls, threat monitoring, and incident response plans specific to voice-based attacks.
Take the Next Step: Transform Your Communication with Ethical Voice Cloning
As organizations adopt voice cloning technologies, platforms that prioritize ethical design, transparency, and regulatory compliance are becoming increasingly important. Whether you are looking to scale your training programs, expand into new markets, improve customer engagement, or enhance accessibility, ethical voice cloning powered by alugha is your competitive advantage. Don’t let your competitors get ahead. Start your voice cloning journey today.
Additional Resources
alugha Case Studies: https://alugha.com/cms/case-studies/
GDPR Compliance at alugha: https://alugha.com/cms/secure-video-hosting/
alugha Pricing: https://alugha.com/cms/pricing/
Frequently Asked Questions
Is voice cloning ethical?
Voice cloning can be ethical when built on a foundation of consent, transparency, and responsible AI practices. The key is ensuring that individuals explicitly authorize the use of their voice and that all AI-generated content is clearly labeled. Platforms like alugha that prioritize these principles from the ground up are setting the standard for ethical voice cloning.
How is voice cloning different from deepfakes?
Voice cloning is a technology; deepfakes are a misuse of that technology. Voice cloning with consent and transparency is a legitimate tool for enterprise communication. Deepfakes, by contrast, use voice cloning without consent to deceive and mislead. The difference lies in intent and authorization.
Is my data safe with alugha?
Yes. alugha is hosted entirely within the European Union and is designed to support GDPR-compliant deployments. All voice data is encrypted and protected with enterprise-grade security measures. The platform is designed to support strong data sovereignty through EU-hosted infrastructure and transparent data governance.
How long does it take to clone a voice?
With alugha, you can clone a voice in minutes. Once the voice model is created, you can generate unlimited voiceovers instantly, without any additional setup.
Can I use voice cloning for customer-facing applications?
Absolutely. Voice cloning is ideal for customer service, marketing, and support applications. With proper transparency and disclosure, customers appreciate the personalization and efficiency that AI voice agents provide.


